

截止至2023年9月份,乐鑫官方提供的语音相关开发框架或库包主要有ESP-ADF、ESP-SR和ESP-Skainet。首先对这三个框架的定位和主要功能进行阐述。
说明:本篇文章有许多内容是从乐鑫相关库/框架的文档中抽取的,同时加上了笔者自己的理解或进一步说明,这样即保证了描述的准确性,也使内容更丰富和深入。
ESP-ADF (Audio Development Framework)
ADF指的是音频开发框架。根据官方介绍,ESP-ADF支持的芯片包括ESP32, ESP32-S2, ESP32-C3, ESP32-C6, 以及 ESP32-S3 。ESP-ADF提供了一套完整工具、示例代码及开发文档,方便开发人员在音频领域进行开发。它为音频应用提供了强大的功能和灵活性,使得开发各种音频应用变得更加便捷。这些音频应用可能是:
- 音乐播放器或录音机:支持多种音频格式,如MP3、AAC、FLAC、WAV、OGG、OPUS、AMR、TS、EQ、混音器(Downmixer)、声音处理器(Sonic)、自动增益控制(ALC)、G.711等。
- 多种音频源:支持HTTP、HLS(HTTP Live Streaming)、SPIFFS、SD卡、A2DP-Source、A2DP-Sink、HFP等。
- 集成媒体协议,例如DLNA、VoIP、RMTP、ESP-RTC(SIP、RTSP和RTCP)等。
- 视频通话、视频录制和视频直播。互联网广播(指通过互联网进行音频或视频广播)。
- 语音识别,并与Alexa、DuerOS等在线服务进行集成。
ESP-ADF的架构设计以及功能将获得的上层支持如下图所示:
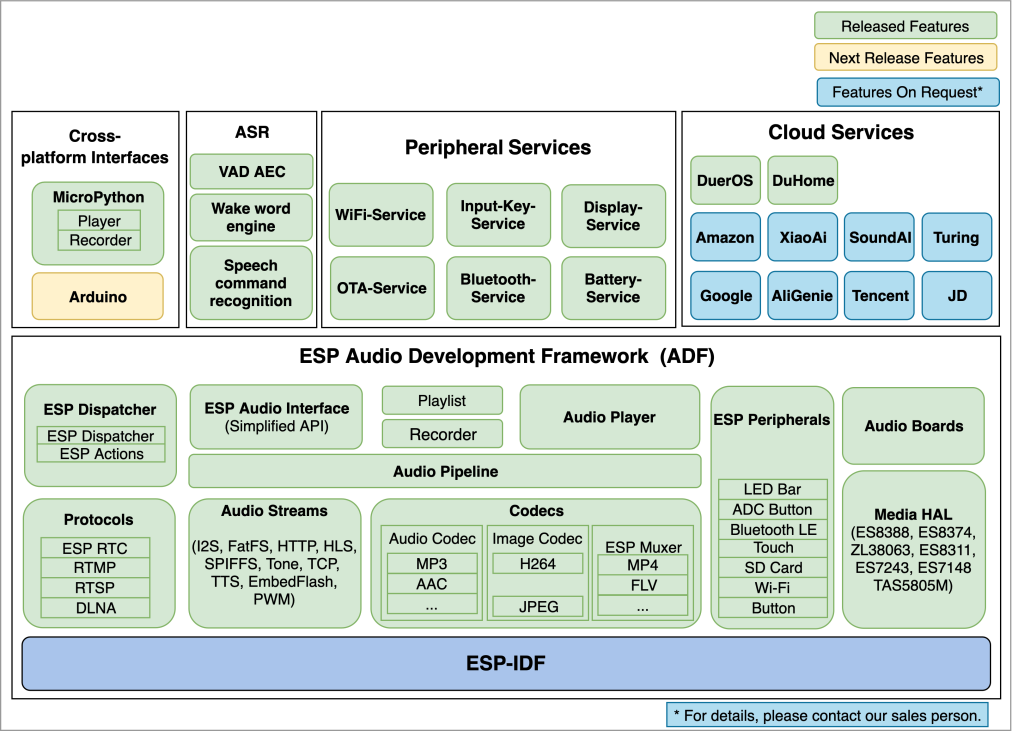
细心的朋友可能发现,上层支持中存在一项ASR (Automatic Speech Recognition, 自动语音识别),这事实上就包括下一节要描述的ESP-SR。我们可以推测,ESP-SR和ESP-Skainet应该是基于ES-ADF框架的!
以下是ESP-ADF 相关文档:
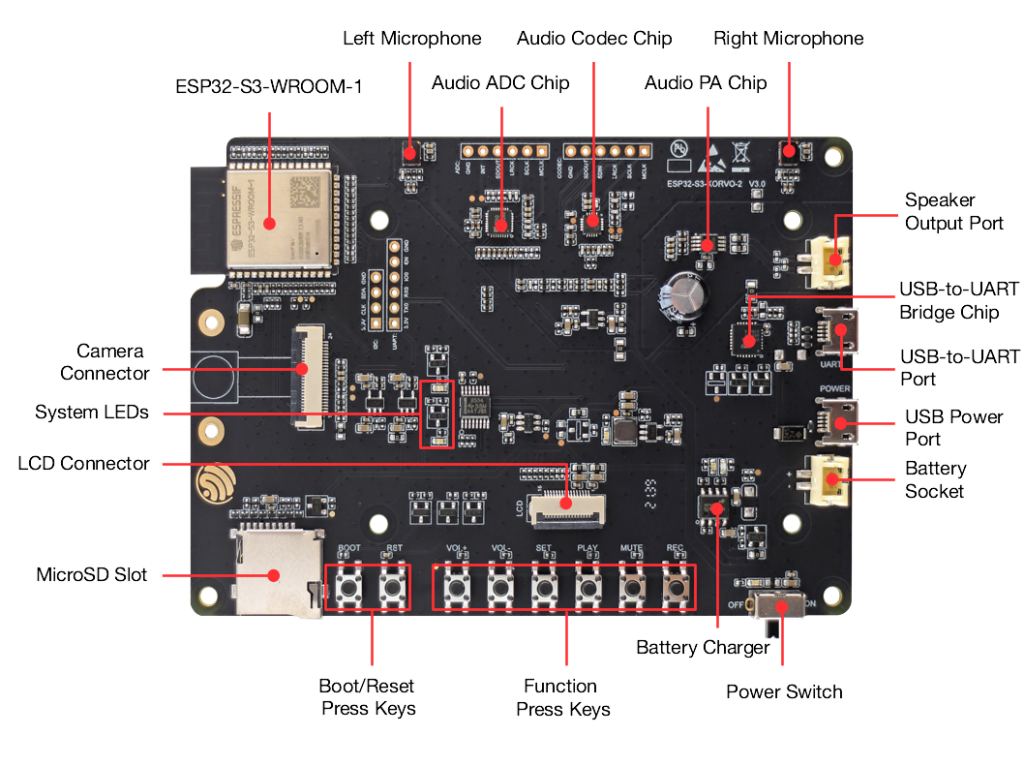
乐鑫官方提供了不少可用于音频应用的开发板,例如ESP32-LyraT、ESP32-S2-Kaluga-1 Kit、ESP32-S3-Korvo-2。
ESP32-S3-Korvo-2
ESP-SR (Speech Recognition Framework)
ESP-SR是乐鑫官方提供的语音识别框架,可用于构建基于ESP32或ESP32-S3芯片(推荐使用ESP32-S3,它支持AI指令和更大、高速的八线SPI PSRAM。新的算法将不再支持ESP32芯片)的人工智能语音解决方案。框架主要包括的模块(这些模块以compenent即组件的方式提供,因此可以选择性地集成到项目中)如下:
- Audio Front-end AFE(声学前端算法框架)
- Wake Word Engine WakeNet(唤醒词模型)
- Speech Command Word Recognition MultiNet(命令词识别模型)
- Speech Synthesis(语音合成,目前仅支持中文)
AFE 声学前端简述
智能语音设备需要在远场噪声环境中,仍具备出色的语音交互性能,声学前端 (Audio Front-End, AFE) 算法在构建此类语音用户界面 (Voice-User Interface, VUI) 时至关重要,因为它可以使用户获得高质量且稳定的音频数据。AFE虽然被设计为一个独立的组件,但事实上也是由多个算法组成:
| 算法名称 | 简介 |
|---|---|
| AEC (Acoustic Echo Cancellation) | 回声消除算法,最多支持双麦处理,能够有效的去除 mic 输入信号中的自身播放声音,从而可以在自身播放音乐的情况下很好的完成语音识别。 |
| NS (Noise Suppression) | 噪声抑制算法,支持单通道处理,能够对单通道音频中的非人声噪声进行抑制,尤其针对稳态噪声,具有很好的抑制效果。 |
| BSS (Blind Source Separation) | 盲信号分离算法,支持双通道处理,能够很好的将目标声源和其余干扰音进行盲源分离,从而提取出有用音频信号,保证了后级语音的质量。 |
| MISO (Multi Input Single Output) | 多输入单输出算法,支持双通道输入,单通道输出。用于在双麦场景,没有唤醒使能的情况下,选择信噪比高的一路音频输出。 |
| VAD (Voice Activity Detection) | 语音活动检测算法,支持实时输出当前帧的语音活动状态。 |
| AGC (Automatic Gain Control) | 自动增益控制算法,可以动态调整输出音频的幅值,当弱信号输入时,放大输出幅度;当输入信号达到一定强度时,压缩输出幅度。 |
| WakeNet | 基于神经网络的唤醒词模型,专为低功耗嵌入式 MCU 设计。 |
在使用时,允许对算法模块进行灵活配置,一方面是选择性地使能算法模块;二是对各个模块的参数进行调整。在编程中可以这样配置:定义一个宏 AFE_CONFIG_DEFAULT() ,它会在展开时生成一个结构体变量的初始化列表。这里使用结构体初始化列表的语法来初始化结构体变量。
afe_config_t afe_config = AFE_CONFIG_DEFAULT();
#define AFE_CONFIG_DEFAULT() { \
// 配置是否使能 AEC
.aec_init = true, \
// 配置是否使能 BSS/NS
.se_init = true, \
// 配置是否使能 VAD(仅用于语音识别场景)
.vad_init = true, \
// 配置是否使能唤醒
.wakenet_init = true, \
// 配置是否使能语音通话(不可与 wakenet_init 同时使能)
.voice_communication_init = false, \
// 配置是否使能语音通话中 AGC
.voice_communication_agc_init = false, \
// 配置 AGC 的增益值(单位为 dB)
.voice_communication_agc_gain = 15, \
// 配置 VAD 检测的操作模式,越大越激进
.vad_mode = VAD_MODE_3, \
// 配置唤醒模型,详见下方描述
.wakenet_model_name = NULL, \
// 配置唤醒模式(对应为多少通道的唤醒,根据mic通道的数量选择)
.wakenet_mode = DET_MODE_2CH_90, \
// 配置 AFE 工作模式(SR_MODE_LOW_COST 或 SR_MODE_HIGH_PERF)
.afe_mode = SR_MODE_LOW_COST, \
// 配置运行 AFE 内部 BSS/NS/MISO 算法的 CPU 核
.afe_perferred_core = 0, \
// 配置运行 AFE 内部 BSS/NS/MISO 算法的 task 优先级
.afe_perferred_priority = 5, \
// 配置内部 ringbuf
.afe_ringbuf_size = 50, \
// 配置内存分配模式,详见下方描述
.memory_alloc_mode = AFE_MEMORY_ALLOC_MORE_PSRAM, \
// 配置音频线性放大 Level,详见下方描述
.agc_mode = AFE_MN_PEAK_AGC_MODE_2, \
// 配置音频总的通道数
.pcm_config.total_ch_num = 3, \
// 配置音频麦克风的通道数
.pcm_config.mic_num = 2, \
// 配置音频参考回路通道数
.pcm_config.ref_num = 1, \
}使用场景介绍
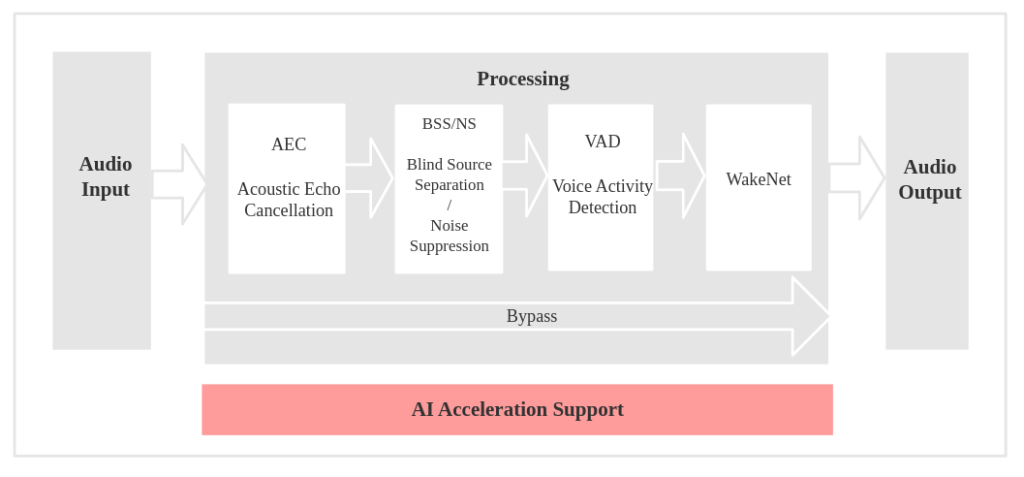
以语音识别场景为例,使用了AEC、BSS/NS、VAD以及WakeNet模块,其工作流程和数据流的设计图如下:
a. 工作流程图
b. 数据流图
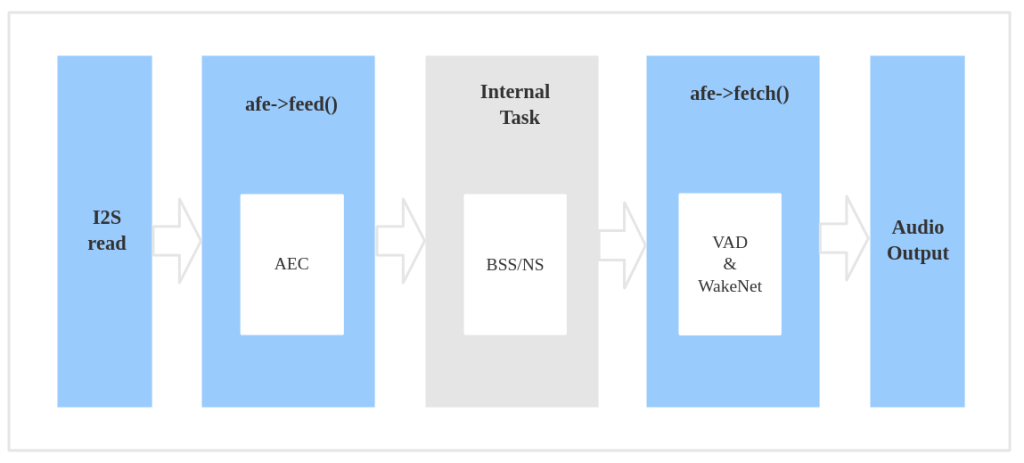
在程序内对数据流进行编程实现的大致过程为:
- 使用
ESP_AFE_SR_HANDLE(),创建并初始化 AFE。注意,voice_communication_init需配置为 false,该配置对应于语音通话场景(afe_config_t结构体中的 wakenet_init 和 voice_communication_init 不可同时配置为 true。)。 - 使用
feed(),输入音频数据。feed 内部会先进行 AEC 算法处理。 - Feed 内部进行 BSS/NS 算法处理。
- 使用
fetch(),获得经过处理过的单通道音频数据及相关信息。这里,fetch 内部可以进行 VAD 处理并检测唤醒词等动作,具体可通过afe_config_t结构体配置。
获取 AFE handle 的命令为:esp_afe_sr_iface_t *afe_handle = &ESP_AFE_SR_HANDLE;
单双麦与输入音频
在嵌入式应用中,使用双麦克风相对于单麦克风有几个优势:
- 声音定位和方向性:双麦克风可以提供更好的声音定位和方向性。通过测量来自不同位置的声音差异,可以确定声源的方向和位置。这对于实现声源追踪、噪声抑制和语音识别等功能非常有用。
- 噪声抑制:使用两个麦克风可以提供更好的噪声抑制效果。通过比较两个麦克风接收到的声音信号,可以将背景噪声与目标声源进行区分,并降低噪声对最终音频质量的影响。
- 回声消除:当使用扬声器播放声音时,可能会出现回声问题。双麦克风可以用于实现回声消除算法,通过在不同位置同时采集声音,准确分析和识别回声信号,并将其从音频信号中去除。
- 环境感知:通过使用多个麦克风,可以更好地感知环境和声音场景。通过分析和比较来自不同麦克风的声音信号,可以了解声音的强度、距离和方向等信息,实现环境感知和智能交互。
但使用双麦克风也会增加硬件成本和复杂性,同时还需要更多的处理资源来处理两个麦克风的信号。
目前,乐鑫 AFE 框架支持单麦和双麦配置。单麦配置,内部Task由NS算法模块处理;双麦配置,内部Task由BSS算法模块处理。此外,若用于语音通话场景(即 wakenet_init = false 且 voice_communication_init = true),则会再增加一个内部 Task 由 MISO 处理。
可根据 esp_afe_sr_iface_op_feed_t() 的输入音频情况,配置所需的音频通道数。具体方式为: 配置 AFE_CONFIG_DEFAULT() 中的 pcm_config 结构体成员:
- total_ch_num:总通道数
- mic_num:麦克风通道数
- ref_num:参考回路通道数
注意,在配置时有如下要求:
- total_ch_num = mic_num + ref_num
- ref_num = 0 或 ref_num = 1 (由于目前 AEC 仅只支持单回路)
在上述要求下,几种支持的配置组合如下:
total_ch_num=1, mic_num=1, ref_num=0
total_ch_num=2, mic_num=1, ref_num=1
total_ch_num=2, mic_num=2, ref_num=0
total_ch_num=3, mic_num=2, ref_num=1在音频处理中,输入信号是需要处理的原始音频信号,并且具有不确定的特征,如频率范围、音量、失真等,而参考信号则是一个已知的信号,用于校准和精确比较输入信号。参考信号通常用于校准输入信号,以调整信号的采样率、增益、平衡等参数,或者进行其他数字信号处理过程。通过使用参考信号进行校准,可以消除因采样率偏差和系统误差引起的时钟漂移和抖动等问题,提高系统的稳定性和准确性。
输出音频
AFE 的输出音频为单通道数据:
- 语音识别场景:在 WakeNet 开启的情况下,输出有目标人声的单通道数据
- 语音通话场景:输出信噪比更高的单通道数据
WakeNet唤醒词识别的实时使能和禁用
当用户在唤醒后需要进行其他操作,比如离线或在线语音识别,这时候可以暂停 WakeNet 的运行,从而减轻 CPU 的资源消耗。此时,仅需调用 disable_wakenet(),进入 Bypass 模式。当后续应用结束后又可以调用 enable_wakenet() 再次使能 WakeNet。ESP32-S3 芯片支持唤醒词切换。在 AFE 初始化完成后,ESP32-S3 芯片可允许用户通过 set_wakenet() 函数切换唤醒词。例如, set_wakenet(afe_data, “wn9_hilexin”) 切换到 “Hi Lexin” 唤醒词。
此外,AEC的使用和WakeNet相似,用户亦可根据自身需求来开启和停止AEC。
更多与AFE相关的内容(如音频数据的feed和fetch、获取音频通道数、资源消耗等)请参考乐鑫ESP-SR官方指南。
WakeNet 唤醒词模型简述
WakeNet 是一个基于神经网络,为低功耗嵌入式 MCU 设计的唤醒词模型,目前支持 5 个以内的唤醒词识别。
WakeNet 的流程图如下:
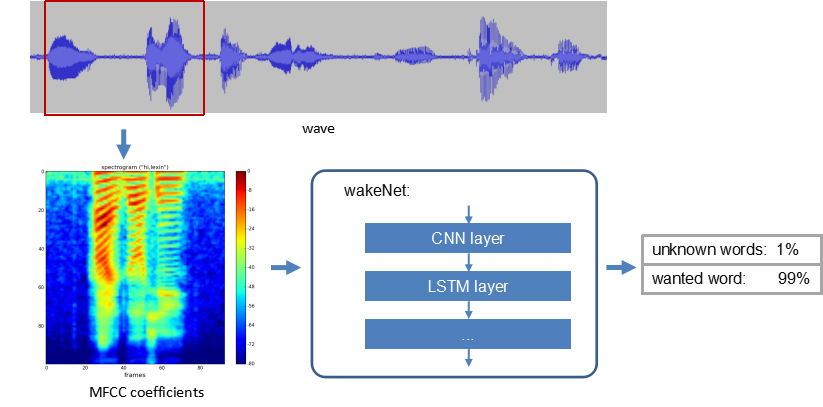
WakeNet的实现原理如下:
- 语音特征 (Speech Feature):我们使用 MFCC 方法提取语音频谱特征。输入的音频文件采样率为 16 KHz,单声道,编码方式为 signed 16-bit。每帧窗宽和步长均为 30 ms。
- 神经网络 (Neural Network):WakeNet模型使用了LSTM层建模,主要是为了处理声音信号的时序特性和长期依赖关系。
- 关键词触发方法 (Keyword Trigger Method):对连续的音频流,为准确判断关键词的触发,我们通过计算若干帧内识别结果的平均值 M,来判断是否触发。当 M 大于指定阈值,则发出触发的命令。
WakeNet不同版本对芯片(ESP32/ESP32S3)的支持可参照官方指南页面给出的表格。
WakeNet 模型使用和运行
目前 ESP-SR 支持的模型加载方式包括“从SPI闪存文件系统(SPIFFS)分区加载”以及“从外部SD卡加载”两种方式。与其他component即组件一样,使用WakeNet前需要使用idf.py menuconfig进行配置。配置项在ESP Speech Recognition选项下。
WakeNet 目前包含在语音前端算法 AFE 中,默认为运行状态,并将识别结果通过 AFE fetch 接口返回。若用户无需使用WakeNet唤醒,需在AFE配置时禁止:afe_config.wakenet_init = False.;若用户希望在运行时临时关闭/打开WakeNet,可在运行过程中调用:afe_handle->disable_wakenet(afe_data)或者afe_handle->enable_wakenet(afe_data)。
其他:关于唤醒词,目前乐鑫以定制服务的方式提供给客户,需要收取模型定制费用。
代码中模型初始化与使用
// step1: 初始化 SPIFFS 并返回 SPIFFS 中的模型
srmodel_list_t *models = esp_srmodel_init();
// step2: 通过关键词选择特定的模型
char *wn_name = esp_srmodel_filter(models, ESP_WN_PREFIX, NULL); // 选择 WakeNet 模型
char *nm_name = esp_srmodel_filter(models, ESP_MN_PREFIX, NULL); // 选择 MultiNet 模型
char *alexa_wn_name = esp_srmodel_filter(models, ESP_WN_PREFIX, "alexa"); // 选择带有 "alexa" 唤醒词的 WakeNet 模型
char *en_mn_name = esp_srmodel_filter(models, ESP_MN_PREFIX, ESP_MN_ENGLISH); // 选择英语的 MultiNet 模型
char *cn_mn_name = esp_srmodel_filter(models, ESP_MN_PREFIX, ESP_MN_CHINESE); // 选择中文的 MultiNet 模型
// 如果直接在代码中使用模型名称,也可以正常运行
char *my_wn_name = "wn9_hilexin"
// 建议检查是否正确加载了模型
if (!esp_srmodel_exists(models, my_wn_name))
printf("%s can not be loaded correctly\n")
// step3: 初始化模型
esp_wn_iface_t *wakenet = esp_wn_handle_from_name(wn_name);
model_iface_data_t *wn_model_data = wakenet->create(wn_name, DET_MODE_2CH_90);
esp_mn_iface_t *multinet = esp_mn_handle_from_name(mn_name);
model_iface_data_t *mn_model_data = multinet->create(mn_name, 6000);MultiNet 命令词识别模型简述
MultiNet 是为了在 ESP32-S3 系列上离线实现多命令词识别而设计的轻量化模型,目前支持 200 个以内的自定义命令词识别。MultiNet 输入为经过前端语音算法(AFE)处理过的音频(格式为 16 KHz,16 bit,单声道)。通过对音频进行识别,则可以对应到相应的汉字或单词。
命令词识别原理如下图所示(命令词识别必须和唤醒搭配使用,当唤醒后可以运行命令词的检测):

MultiNet 支持多种且灵活的命令词设置方式,可通过在线或离线方法设置命令词,还允许随时动态增加/删除/修改命令词。MultiNet5和MultiNet6使用汉语拼音作为基本识别单元。比如“打开空调”,应该写成 “da kai kong tiao”。不同版本的MultiNet命令词格式不同(MultiNet6通过修改model/multinet_model/fst/commands_cn.txt,而MultiNet5则通过menuconfig配置)。
注意,单个 Command ID 可以支持多个短语,比如“打开空调”和“开空调”表示的意义相同,则可以将其写在同一个 Command ID 对应的词条中,如:(da kai kong tiao,kai kong tiao) ID0。用英文字符“,”隔开相邻词条(“,”前后无需空格)。指令还可以通过调用 API 修改,这种方法对于不同版本的模型都适用,相关接口可参考通过调用API修改。
MultiNet 模型使用和运行
当用户开启 AFE 且使能 WakeNet 后,则可以运行 MultiNet。但需要注意以下几点要求:
- 传入帧长和 AFE fetch 帧长长度相等。确定需要传入 MultiNet 的帧长:
int mu_chunksize = multinet->get_samp_chunksize(model_data);。mu_chunksize 是需要传入 MultiNet 的每帧音频的 short 型点数,这个大小和 AFE 中 fetch 的每帧数据点数完全一致。 - 支持音频格式为 16 KHz,16 bit,单通道。AFE fetch 拿到的数据也为这个格式。
- MultiNet 识别:将 AFE 实时 fetch 到的数据送入以下 API:
esp_mn_state_t mn_state = multinet->detect(model_data, buff);。buff 的长度为mu_chunksize * sizeof(int16_t)。
MultiNet 识别结果
命令词模型在运行时,会实时返回当前帧的识别状态 mn_state ,目前分为以下几种识别状态:
- ESP_MN_STATE_DETECTING:该状态表示目前正在识别中,还未识别到目标命令词。
- ESP_MN_STATE_DETECTED:该状态表示目前识别到了目标命令词。
- ESP_MN_STATE_TIMEOUT:该状态表示长时间未检测到命令词,自动退出。等待下次唤醒。
单次识别模式和连续识别模式: 当命令词识别返回状态为 ESP_MN_STATE_DETECTED 时退出命令词识别,则为单次识别模式; 当命令词识别返回状态为 ESP_MN_STATE_TIMEOUT 时退出命令词识别,则为连续识别模式。(通过连续识别——直到某帧识别不出关键词,可能获取到多个关键词)
识别结果获取:当识别状态为ESP_MN_STATE_DETECTED,可以调用 get_results 接口获取识别结果。
esp_mn_results_t *mn_result = multinet->get_results(model_data);识别结果的信息存储在 get_result API 的返回值中,返回值的数据类型如下:
typedef struct{
esp_mn_state_t state;
int num; // The number of phrase in list, num<=5. When num=0, no phrase is recognized.
int phrase_id[ESP_MN_RESULT_MAX_NUM]; // The list of phrase id.
float prob[ESP_MN_RESULT_MAX_NUM]; // The list of probability.
} esp_mn_results_t;用户可以使用 phrase_id[0] 和 prob[0] 拿到概率最高的识别结果:
state为当前识别的状态num表示识别到的词条数目, num <= 5,即最多返回 5 个候选结果phrase_id表示识别到的词条对应的 Phrase IDprob表示识别到的词条识别概率,从大到到小依次排列
ESP-Skainet
ESP-Skainet 是乐鑫推出的智能语音助手,目前支持唤醒词识别和命令词识别。ESP-Skainet 以最便捷的方式支持基于乐鑫的 ESP32系列 芯片的唤醒词识别和命令词识别应用程序的开发。ESP-Skainet 的功能支持如下所示:
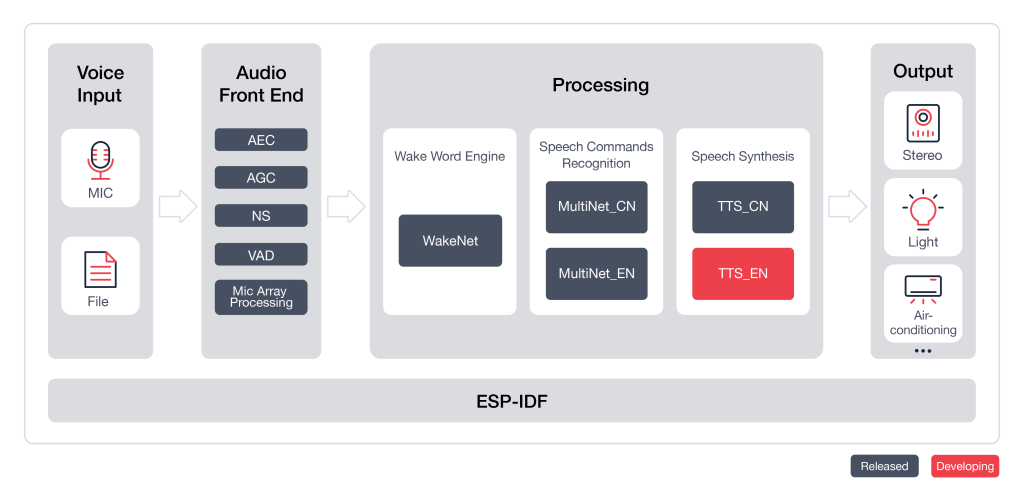
ESP-Skainet官方示例及支持的开发板详见该链接。
ESP-Skainet的输入音频流可以来自麦克风,或Flash/TF 卡中的 wav/pcm 等音频文件文件。
从上面的描述发现,ESP-Skainet与ESP-SR的功能重合度很好,那么二者之间有什么关联呢。实际上,在ESP-Skainet中,ESP-SR是直接作为其中一个组件提供的:
esp-skainet
├── esp-sr
├── esp_codec_dev
├── hardware_driver
├── led_strip
├── perf_tester
├── player
└── sr_ringbufESP-SR 组件包含了 ESP-Skainet 中的 API, 包括唤醒词识别、语音命令词识别和前端声学算法。除此之外,ESP-Skainet还有其他这些组件:
- esp_codec_dev:为音频编解码器设备提供驱动的组件,用于支持音频流的编解码操作。
- hardware_driver:硬件驱动库,提供与硬件设备(如声音芯片、灯带等外部设备)进行交互的功能。提供乐鑫开发板的BSP。
- led_strip:用于控制 LED 灯带的库。它提供了控制灯带颜色和亮度的功能。
- perf_tester:性能测试工具,用于评估和优化 ESP-Skainet 在 ESP32 上的性能表现。
- player:用于音频播放的库,可以将音频数据传递给 DSP(数字信号处理器)进行播放。
- sr_ringbuf:ESP-Skainet 的环形缓冲区库,用于存储和管理音频流数据。
关于BSP(Board Support Package):针对特定硬件平台或嵌入式系统的支持软件包。它提供了与硬件平台相关的驱动程序、库文件和操作系统接口等,以方便开发者在该平台上进行软件开发。BSP 的主要作用是将硬件抽象化,隐藏底层硬件细节,为上层软件提供统一的接口和功能。通过使用 BSP,开发人员可以更方便地在特定嵌入式平台上进行应用程序开发,而不必直接与底层硬件进行交互。它包含了适配硬件的设备驱动程序,例如处理器、内存、外设等的初始化和控制代码。此外,BSP 还可能提供操作系统适配层和中间件,以便更好地支持特定硬件平台上的应用程序开发。通常,BSP 的内容涵盖了硬件初始化、时钟管理、中断控制、设备驱动、文件系统支持、网络协议栈、显存管理等。需要注意的是,BSP 是与具体硬件平台紧密相关的,不同硬件平台之间的 BSP 是不兼容的,因为各个硬件平台的底层架构、外设配置和接口规范都可能存在差异。以esp-skainet/master/components/hardware_driver/boards/esp32s3-box/bsp_board.c为例:
// 初始化 I2C 总线,并设置时钟速度
esp_err_t bsp_i2c_init(i2c_port_t i2c_num, uint32_t clk_speed)
// 初始化音频 CODEC 的 ADC(模数转换器)功能,并设置采样率
esp_err_t bsp_codec_adc_init(int sample_rate)
// 初始化音频 CODEC 的 DAC(数模转换器)功能,并设置采样率、通道格式和每个通道的位数
esp_err_t bsp_codec_dac_init(int sample_rate, int channel_format, int bits_per_chan)
// 关闭音频 CODEC 的 ADC 功能
static esp_err_t bsp_codec_adc_deinit()
// 关闭音频 CODEC 的 DAC 功能
static esp_err_t bsp_codec_dac_deinit()
// 设置音频播放的音量
esp_err_t bsp_audio_set_play_vol(int volume)
// 获取当前音频播放的音量
esp_err_t bsp_audio_get_play_vol(int *volume)
// 初始化 I2S 接口,并设置采样率、通道格式和每个通道的位数
static esp_err_t bsp_i2s_init(i2s_port_t i2s_num, uint32_t sample_rate, int channel_format, int bits_per_chan)
// 关闭 I2S 接口
static esp_err_t bsp_i2s_deinit(i2s_port_t i2s_num)
// 初始化音频 CODEC,并设置 ADC 和 DAC 的采样率、通道格式和每个通道的位数
static esp_err_t bsp_codec_init(int adc_sample_rate, int dac_sample_rate, int dac_channel_format, int dac_bits_per_chan)
// 关闭音频 CODEC
static esp_err_t bsp_codec_deinit()
// 播放音频数据,传入音频数据指针、数据长度和等待时间
esp_err_t bsp_audio_play(const int16_t* data, int length, TickType_t ticks_to_wait)
// 获取音频数据,可选择获取原始通道数据或者处理后的数据
esp_err_t bsp_get_feed_data(bool is_get_raw_channel, int16_t *buffer, int buffer_len)
// 获取当前音频数据的通道数
int bsp_get_feed_channel(void)
// 初始化音频板上的硬件接口,设置采样率、通道格式和每个通道的位数
esp_err_t bsp_board_init(audio_hal_iface_samples_t sample_rate, int channel_format, int bits_per_chan)
// 初始化 SD 卡,并设置挂载点和最大文件数量
esp_err_t bsp_sdcard_init(char *mount_point, size_t max_files)这些函数提供了在 ESP32-S3 开发板上操作音频、I2C 总线、I2S 接口和 SD 卡等硬件功能的能力,使开发者可以方便地配置和使用这些硬件模块。
esp_codec_dev的说明
esp_codec_dev 是为音频编解码器设备提供驱动的组件,可以为用户提供便捷的上层 API 来实现播放和录音功能。目前支持以下功能:
- 提供常用音频编解码器设备的驱动
- 支持音频编解码器设备的多实例 (包括同类型设备)
- 提供统一的抽象化接口来操作编解码器设备
- 支持客户定制化编解码器设备 (仅需实例化提供的接口)
- 为播放和录音提供易用的上层 API
- 支持软件音量调节 (硬件不支持音量调节时)
- 支持定制化音量曲线以及音量控制实现
- 兼容多平台仅需替换平台
架构预览
以编解码器设备 (ES8311) 为例,下面分别介绍硬件框图和软件架构。编解码器设备 (ES8311) 和主芯片(ESP32-S3) 之间的硬件连接简图如下:
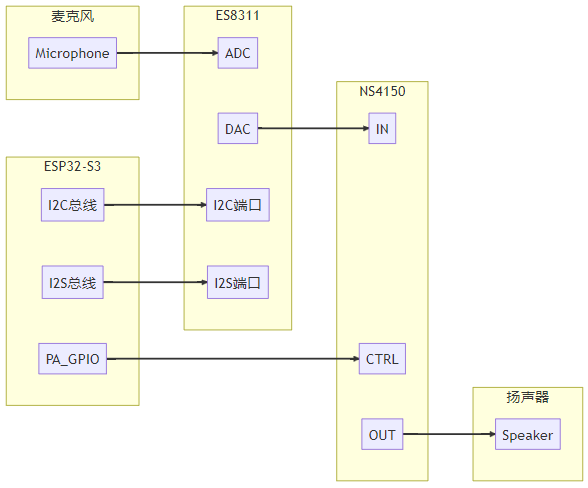
ESP32-S3 通过 I2C 总线向 ES8311 发送控制命令,通过 I2S 总线传递音频数据。在播放过程中, ES8311 从 I2S 总线接收数字音频数据进行数模转换后发送给功放芯片(NS4150), 最后发送给扬声器输出声音。在录音过程中,ES8311将从麦克风采集到的模拟信号放大,进行模数转换后发送给 ESP32-S3。 ESP32-S3 同 ES8311 在以下两个通道进行通讯:
- 控制通道:用来配置编解码器设备 (通过 I2C 总线)
- 数据通道: 用来交换音频数据 (通过 I2S 总线)
软件架构上,对硬件行为进行了下述抽象:

通讯通道抽象为两种接口(interface):
audio_codec_ctrl_if_t控制接口: 主要提供read_reg和write_regAPI 来配置编解码器设备
常用控制通道包括 I2C, SPI 等audio_codec_data_if_t数据接口: 主要提供read和writeAPI 用来交换音频数据
常用数据通道包括 I2S, SPI 等
esp_codec_dev 由 audio_codec_data_if_t 和 audio_codec_if_t 组成。audio_codec_if_t 对编解码器控制操作进行抽象,通过编解码器特有的配置参数构建(由 audio_codec_ctrl_if_t 和audio_codec_gpio_if_t 通过 es8311_codec_cfg_t 进行配置)。audio_codec_gpio_if_t 对 IO 控制进行抽象,以适配主控 IO 或者扩展芯片 IO, 在编解码器内部进行调用用以匹配特有的设定时序。
在文件esp-skainet\components\esp_codec_dev\esp_codec_dev.c中,定义了结构体codec_dev_t(注意:成员变量不包括audio_codec_ctrl_if_t 和audio_codec_gpio_if_t两种结构体)。
typedef struct {
const audio_codec_if_t *codec_if;
const audio_codec_data_if_t *data_if;
const audio_codec_vol_if_t *sw_vol;
esp_codec_dev_type_t dev_caps;
bool input_opened;
bool output_opened;
int volume;
float mic_gain;
bool muted;
bool mic_muted;
bool sw_vol_alloced;
esp_codec_dev_vol_curve_t vol_curve;
bool disable_when_closed;
} codec_dev_t;使用方法(本段直接摘录esp_codec_dev文档)
以 ES8311 为例,下面将演示播放和录音的具体步骤:
- 为编解码器设备的控制和数据总线安装驱动,可参考test_board.c
ut_i2c_init(0);
ut_i2s_init(0);- 为编解码器设备实现控制接口,数据接口和 GPIO 接口 (使用默认提供的接口实现)
audio_codec_i2s_cfg_t i2s_cfg = {
#if ESP_IDF_VERSION >= ESP_IDF_VERSION_VAL(5, 0, 0)
.rx_handle = i2s_keep[0]->rx_handle,
.tx_handle = i2s_keep[0]->tx_handle,
#endif
};
const audio_codec_data_if_t *data_if = audio_codec_new_i2s_data(&i2s_cfg);
audio_codec_i2c_cfg_t i2c_cfg = {.addr = ES8311_CODEC_DEFAULT_ADDR};
const audio_codec_ctrl_if_t *out_ctrl_if = audio_codec_new_i2c_ctrl(&i2c_cfg);
const audio_codec_gpio_if_t *gpio_if = audio_codec_new_gpio();- 基于控制接口和 ES8311 特有的配置实现
audio_codec_if_t接口
es8311_codec_cfg_t es8311_cfg = {
.codec_mode = ESP_CODEC_DEV_WORK_MODE_BOTH,
.ctrl_if = out_ctrl_if,
.gpio_if = gpio_if,
.pa_pin = YOUR_PA_GPIO,
.use_mclk = true,
};
const audio_codec_if_t *out_codec_if = es8311_codec_new(&es8311_cfg);- 通过 API
esp_codec_dev_new获取esp_codec_dev_handle_t句柄。参考下面代码用获取到的句柄来进行播放和录制操作:
esp_codec_dev_cfg_t dev_cfg = {
.codec_if = out_codec_if; // es8311_codec_new 获取到的接口实现
.data_if = data_if; // audio_codec_new_i2s_data 获取到的数据接口实现
.dev_type = ESP_CODEC_DEV_TYPE_IN_OUT; // 设备同时支持录制和播放
};
esp_codec_dev_handle_t codec_dev = esp_codec_dev_new(&dev_cfg);
// 以下代码展示如何播放音频
esp_codec_dev_set_out_vol(codec_dev, 60.0);
esp_codec_dev_sample_info_t fs = {
.sample_rate = 48000,
.channel = 2,
.bits_per_sample = 16,
};
esp_codec_dev_open(codec_dev, &fs);
uint8_t data[256];
esp_codec_dev_write(codec_dev, data, sizeof(data));
// 以下代码展示如何录制音频
esp_codec_dev_set_in_gain(codec_dev, 30.0);
esp_codec_dev_read(codec_dev, data, sizeof(data));
esp_codec_dev_close(codec_dev);关于环形缓冲区
环形缓冲区(Ring Buffer),也被称为循环缓冲区或环形队列,是一种常用的数据结构,用于在固定大小的缓冲区中存储数据。它具有固定大小的缓冲区,并使用两个指针来标识缓冲区的开头和结尾。
环形缓冲区的特点是当写入数据到达缓冲区的末尾时,会绕回到缓冲区的开头继续写入。同样地,当读取数据到达缓冲区的末尾时,会绕回到缓冲区的开头继续读取。这种循环的方式使得环形缓冲区可以有效地利用有限的内存空间,并支持连续的数据读写操作。
环形缓冲区常被用于临时存储数据,特别适用于生产者-消费者模型,在数据的产生和消耗速率不一致的情况下,实现数据的流式传输。
在 ESP-Skainet 中,sr_ringbuf 组件就是一个环形缓冲区库,用于存储和管理音频流数据。它可以作为数据的中间存储,用于在处理音频数据时进行缓冲和传递,确保数据在各个组件之间的可靠流动。












请登录后查看评论内容