

LLMs 简介
大语言模型(Large Language Model,LLM)是一种基于深度学习的自然语言处理(NLP)模型。LLM其实包含两层含义,一是语言模型(Language Model)、二是大模型(Large Model)。前者指的是一种基于统计学或机器学习的模型,用于对自然语言的规律和概率进行建模。其主要目标是根据给定的上下文预测下一个单词、短语或句子的概率分布;后者指参数量非常庞大、拥有数十亿至数千亿个参数的深度学习模型。随着计算硬件的升级以及数据集的不断扩大,大模型已经成为现代深度学习领域的重要研究方向。LLM的出现推动了自然语言处理领域的发展,并在很多应用场景中展现出了巨大的潜力。
主流大模型与架构
当前流行的大模型的网络架构其实并没有很多新的技术,还是一直沿用当前NLP领域最热门最有效的架构——Transformer结构。国际主流大模型基本上都是基于Transformer架构构建的,因此可以说Transformer架构是支撑现代大模型的基础结构之一。相比于传统的循环神经网络(RNN)和长短时记忆网络(LSTM),Transformer具有独特的注意力机制(Attention),这相当于给模型加强理解力,对更重要的词能给予更多关注,同时该机制具有更好的并行性和扩展性,能够处理更长的序列。
以下是国际上主流的部分大模型:
(1)GPT(Generative Pre-trained Transformer)
(2)LLaMA(Language Model for Many Applications)
(3)BLOOM(BigScience Large Open-science Open-access Multilingual Language Model)
(4)LaMDA(Language Model for Dialogue Applications)或BARD
国内针对中文进行优化的大模型主要有:
(1)ChatGLM
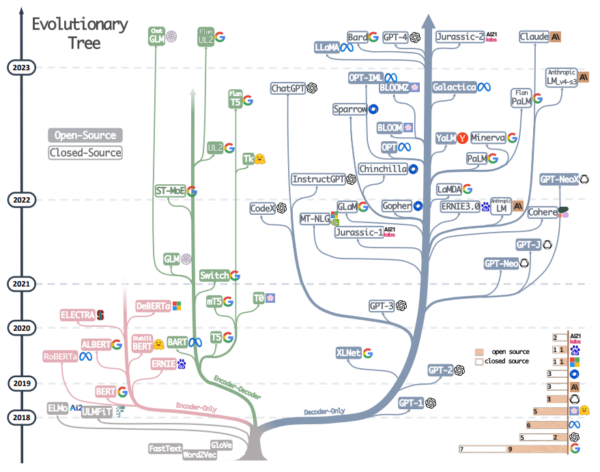
下图较全面地展示了大模型的“进化”过程。
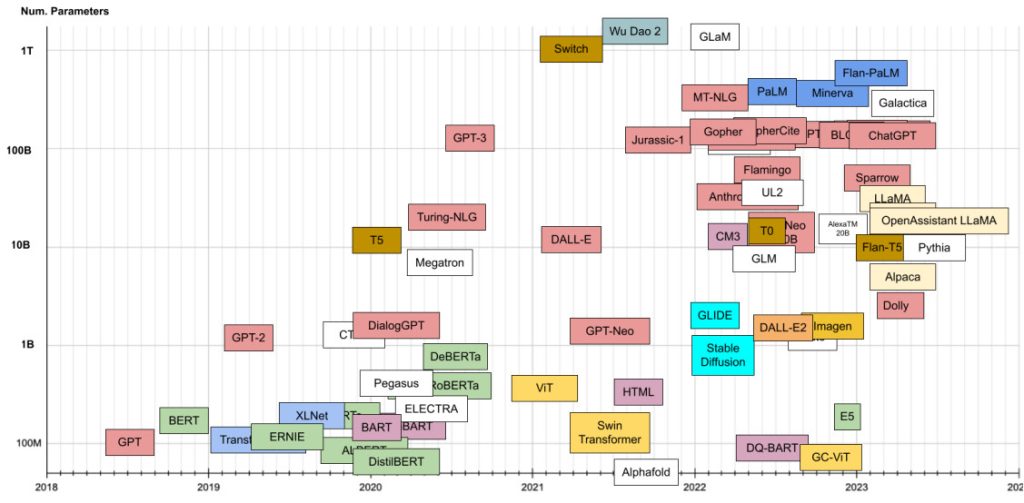
大模型的参数量也是一个值得探讨的话题。下图给出了主流模型的参数数量。
大模型应用场景
目前大模型已经开始在许多领域进行产品化落地,除了“声名显赫”的ChatGPT产品外,主要还有以下一些主流的应用:
(1)辅助办公类产品
微软在使用大型模型方面进行了尝试,成功地将其应用于旗下的Office系列软件中。例如,用户可以在Word中获得文档总结和编辑建议,并且可以对所给的文章进行摘要生成;在Excel中,用户可以通过自然语言描述直接处理数据,提高了软件的易用性;在PowerPoint中,用户只需提出要求,就能自动生成一份展示内容;在Outlook中,用户可以直接使用自然语言来生成邮件内容,实现了真正的AI秘书。
(2)代码生成类产品
利用这类产品,工程师可以通过对话方式直接生成各种功能代码,包括辅助编写测试用例、解释代码片段和调试程序问题,这一功能带来了革命性的进步,有效解放了程序员的生产力。开发人员能够更加专注于业务理解、系统设计和架构设计等高级需求,从而提升软件开发的效率和质量。这种创新的方式使得程序员能够更好地利用自己的时间和精力,将关注点集中在核心业务领域,推动软件工程领域的发展和进步。
(3)教育知识类产品
例如,通过使用问答的方式,ChatPDF能够快速提取、理解和总结论文的重要内容,从而极大地提升了阅读新论文的效率。再如,语言学习者可以通过与Call Annie进行对话来提升口语表达能力,无需担心时间和地点的限制。
(4)搜索引擎和推荐系统
大型模型在搜索引擎和推荐系统中的应用,可以帮助提高用户的搜索和浏览体验,提供更准确和个性化的结果:大型模型可以帮助搜索引擎更准确地理解用户的查询意图,并提供相关的搜索结果。传统的搜索引擎主要依赖关键词匹配,但是随着大型模型的出现,搜索引擎可以根据用户查询的语义和上下文进行更深入的理解,并提供更具相关性和多样性的搜索结果;大型模型可以帮助推荐系统更好地理解用户的兴趣和偏好,并提供个性化的推荐内容。传统的推荐系统主要基于协同过滤和基于内容的方法,但是大型模型可以通过学习用户的历史行为和上下文信息,提供更精准和多样化的推荐结果。
(5)大模型定制化服务
定制化大模型可以通过微调和优化来适应特定领域的数据和问题,从而提供更准确和高效的解决方案。这样的定制化服务对于需要处理特定行业或领域专业问题的企业非常有吸引力。例如在某些垂直领域,包括工业领域,医药领域,管理领域等场景下进行专业问题,研究型问题的使用依然需要特定场景的数据进行微调,这种定制化的服务也能给企业带来巨大的效率提升和节省成本的收益,属于比较有前景的业务。
(6)计算相关上下游相关产业
大型模型的出现和发展,涉及到了许多计算相关上下游相关产业,主要包括芯片制造、云计算服务、数据处理和存储、大模型应用开发。除此之外,还涌现了一些大模型微调框架,它们提供丰富了API和工具,用以简化模型开发和训练的流程。
大模型评估
HuggingFace维护的开源LLM排行榜单。
LLM的若干关键技术
提示工程(Prompt Engineering)
Prompt是用于处理和优化输入提示文本的一种技术,尤其在自然语言处理(NLP)领域,是一个关键的交互和引导机制。Prompt可以被理解为一种精心设计的输入或指令,用来触发预训练模型(如GPT-3、BERT等)生成特定类型的文本输出或者执行某种任务。通过合理设计和选择Prompt,可以显著影响模型生成的输出结果。
深度学习架构
自注意力机制(Self-Attention Mechanism),如Transformer架构,这是LLMs的核心组成部分,使得模型能够更好地捕捉长距离依赖关系,并在大规模数据集上进行高效训练。
预训练与微调
在LLMs领域,预训练指的是模型先在海量未标注文本数据上进行自监督学习,学习语言的一般模式和结构。通过预训练,模型可以学习到大量的语言知识和上下文关系,从而提高后续任务的表现能力。
微调是指在特定任务(如问答、文本分类等)的标记数据上对预训练模型进行进一步训练和优化的过程。通过微调,模型可以适应具体任务的特点和数据分布,提高任务性能。
多模态
对于多模态大语言模型(MLLM),还需要整合视觉、听觉等不同模态信息的学习能力,通过联合训练让模型理解多种输入类型。
从开源微调库观察LLM的开发特点
LLMs 训练和微调技术
LLMs 领域中的数据预处理
一般步骤:自定义数据集、数据清洗、转换并适应模型输入格式
关键环节和处理工具:
Tokenizer分词器
SentencePiece词表训练
模型训练和微调(主要将微调)
高效参数微调
Lora、
DeepSpeed框架简介
顺带介绍微调库
ChatGLM3微调实践
GLM家族介绍
微调过程
环境
数据准备
训练过程
部署和验证
拓展
LLM应用框架LangChain













请登录后查看评论内容