

前言
最近计划借助M5Stack的Core2开发板(基于乐鑫ESP32芯片)实现一个智能语音助手,能够通过语音交互与用户进行对话和执行一些简单的任务。为了简化开发过程、降低项目难度,我原本是希望能够直接使用官方提供的SDK(M5Unified或M5Core2)实现全部功能,包括设备端的语音唤醒,但在实际操作时,才发现官方并没有提供语音识别或唤醒的方案。于是我也转而尝试乐鑫提供的音频开发工具ESP-ADF,但ESP-ADF的例程是适配乐鑫自己的开发板的,例如ESP32-LyraT。这些板子都使用了音频编解码芯片,而M5Core2则不具备,这也加大了移植难度——虽然可以实现,但过程可能会十分坎坷!除了引脚定义不同之外,还需要把例程中使用了编解码器功能的部分都去掉或者换成纯软件实现(看了ESP-SR的框架图是可以直接使用麦克风录制的PCM音频源,不涉及音频编解码,感兴趣的小伙伴可以尝试在M5Core2实现一下语音唤醒功能)。好在,M5Core2上仍然可以通过其内置的扬声器和麦克风实现基本的音频播放和录制功能,这就足够了,而且这些功能可以直接通过官方SDK来实现。我们完全可以将语音唤醒、语音识别以及语音合成的功能交给云端去做。
语音唤醒框架——Porcupine
接触过语音唤醒开发的小伙伴可能知道Snowboy,它是由KITT.AI开发、基于深度学习的跨平台轻量级语音唤醒引擎。可惜的是,在2020后官方便不再对它进行维护。时至今日,我们仍然可以看到一些个人开发者在使用snowboy,但对于我个人来说,我更愿意使用年轻、活跃度高的项目。我把目光投向了Porcupine。鉴于国内目前对它的介绍和使用较少,而我刚好正需要使用它,于是便有了这篇文章。一方面介绍一下Porcupine的基本使用方法,一方面也作为自己的学习记录。
Porcupine是一个高精度和轻量级的语音唤醒引擎,可用于始终处于监听状态的语音应用程序。它使用在真实环境中训练的深度神经网络,具有紧凑和计算效率高的特点,非常适合物联网应用。Porcupine是跨平台的,支持多种硬件设备和操作系统,包括:
- 芯片:Arm Cortex-M, STM32, Arduino, and i.MX RT
- 单板机:Raspberry Pi, NVIDIA Jetson Nano, and BeagleBone
- 移动设备系统:Android and iOS
- 桌面浏览器:Chrome, Safari, Firefox, and Edge
- 桌面操作系统:Linux (x86_64), macOS (x86_64, arm64), and Windows (x86_64)
同时,Porcupine也支持众多开发语言,并为它们提供了相应的SDK。
Porcupine具有可扩展性,能够在不增加运行时开销的情况下检测多个始终监听的语音命令。开发者可以通过Picovoice-Console自助训练自定义的唤醒词模型。小伙伴们可以通过项目地址以及控制台进一步了解Picovoice的特性和使用方式。
注意:在使用Porcupine的SDK时会要求用户提供密钥(AccessKey),该密钥需要提前在前面说到的控制台获取。官方使用密钥的目的是实现授权以及跟踪和管理用户使用情况,以便进行许可证验证和付费计费等操作(Picovoice有许多产品,密钥是通用的。Porcupine不对免费用户做调用次数和调用时间的限制,可以放心使用!)。
一个简单的尝试:使用Python实现语音唤醒功能
开发环境(需要准备好麦克风):
- 软件环境:Win10、Anaconda、Python3.7
- 硬件环境:PC、华硕C920摄像头麦克风
借助Python实现Porcupine语音唤醒功能的第一步是安装其Python库——pvporcupine。我习惯使用Anaconda+virtualenv双虚拟环境进行开发:首先进入Anaconda环境,接着在Anaconda环境下创建virtualenv虚拟环境,最后安装pvporcupine:
conda activate py372
virtualenv venv
.\venv\Scripts\activate.bat
pip install pvporcupine如果你不需要虚拟环境,只运行pip3 install pvporcupine安装即可。由于我们在这个例子中需要进行录音,因此还需要安装一个用于录制PCM音频数据的工具库,这里使用Picovoice提供的开源工具——PvRecorder。PvRecorder 的一个主要用途是为声学模型的训练和评估提供标注的语音数据集。在 Picovoice 的语音识别和唤醒词引擎的开发过程中,PvRecorder 也被广泛地应用。当然,你也可以尝试使用Pyaudio库进行开发。安装PvRecorder的命令为:
pip3 install pvrecorder最后,只需要运行一下脚本,就能实现语音唤醒功能,是不是很简单!
import pvporcupine
from pvrecorder import PvRecorder
access_key = "your_access_key"
keywords = ["alexa", "hey siri", "jarvis"]
porcupine = pvporcupine.create(access_key=access_key, keywords=keywords)
recoder = PvRecorder(device_index=-1, frame_length=porcupine.frame_length)
try:
recoder.start()
while True:
keyword_index = porcupine.process(recoder.read())
if keyword_index >= 0:
print(f"Detected {keywords[keyword_index]}")
except KeyboardInterrupt:
recoder.stop()
finally:
porcupine.delete()
recoder.delete()请记得将上面的access_key字符串替换为你自己的密钥。在上面的示例程序中,我制定了三个唤醒词,它们是[“alexa”, “hey siri”, “jarvis”]。截至文章投稿时,Pvporcupine默认支持的英文唤醒词包括:grasshopper, bumblebee, americano, hey google, pico clock, ok google, alexa, porcupine, hey siri, computer, picovoice, hey barista, jarvis, blueberry, grapefruit, terminator。是不是对其中一些唤醒词感到熟悉,不妨逐个了解一下!
在程序顺利运行时,如果你对着麦克风说出指定的唤醒词,终端就会进行实时输出:

从此次试验结果来看,Pvporcupine对英文唤醒词的识别效果(准确性和灵敏度)还是不错的,对于个人开发者来说完全足够了。从官方介绍来看,Pvporcupine是达到商用标准的。
进阶:唤醒词训练并定制自己的模型
Porcupine自定义唤醒词非常简单便捷。首先登陆Picovoice控制台,转到Porcupine页面。接着选择目标语言(普通话选择Mandarin)、平台并输入需要设置的唤醒词。这里,我使用的自定义唤醒词是“小智”。在选择唤醒词后,还可以在页面上测试唤醒效果,这时候会弹出”使用麦克风设备权限”的弹窗,需要选择允许。
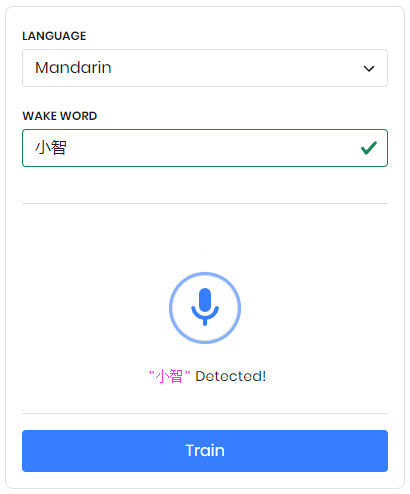
再一切准备就绪后就可以点击Train按钮,此时会要求选择部署的平台,这里我选择的平台是Windows平台。训练完页面会输出文件下载提示,用户点击下载后会获得一个唤醒词文件。有了唤醒词文件,我们还需要在程序中指定唤醒模型,因为默认模型只支持英文,需要更换为中文模型。各语言模型文件可在该页面获取。
最关键的一步来啦,我们只需要替换小节“一个简单的尝试:使用Python实现语音唤醒功能”中的部分代码,便可以使用支持我们自定义中文唤醒词的语音唤醒功能。将第6~8行的内容替换为以下代码:
keywords = ["小智"]
porcupine = pvporcupine.create(
access_key=access_key,
keyword_paths=['E:/BlogResources/Picovoice Porcupine/小智_zh_windows_v2_2_0/小智_zh_windows_v2_2_0.ppn'],
model_path='E:/BlogResources/Picovoice Porcupine/小智_zh_windows_v2_2_0/porcupine_params_zh.pv'
)运行程序,体验一番自定义唤醒词的趣味吧!










请登录后查看评论内容