

在配置深度学习环境时,容易踩到不少坑,例如GPU驱动和CUDA版本不匹配、网络问题导致下载速度缓慢、虚拟环境Conda或VirtuaEnv配置等。这篇文章详细记录了整个配置过程,希望对大家有所帮助!
(题外话:组装这部工作站的缘由是我想把PC进行升级,但又舍不得旧配件,于是便在二手鱼上淘了块3090,搭配我的老配件组装了这部工作站,所以在硬件搭配上有不少优化空间)
环境
硬件配置
- CPU: i7 8700K
- GPU: RTX 3090 24G
- 内存: 32G x2 DDR4 2666
- 硬盘: 500GB SSD + 256G SSD + 2TB HDD
- 电源: 1000W 先马黑钻
系统配置
- Ubuntu 22.04 LTS
- Python 3.9.17
- Anaconda 22.9.0
备注:强烈建议在开始进行后续步骤前,提前配置好SSH登录,这样在遇到显卡驱动问题导致无法进入桌面时也能通过SSH进行配置。
英伟达显卡驱动安装
网络上流行的旧做法是…,大多提到…。但这里推荐采用Nvidia官方推荐的做法,笔者也是一次性成功。
sudo apt-get install nvidia-driver-510-server安装后需要重启系统
sudo reboot重启后通过NVIDIA显卡驱动提供的命令行工具nvidia-smi确定显卡驱动是否安装成功。
nvidia-smi备注:nvidia-smi主要用于监视和管理NVIDIA GPU设备的信息,会显示当前系统上安装的NVIDIA GPU设备的详细信息。这包括GPU型号、驱动版本、GPU使用率、温度、显存使用情况、功耗等。
Anaconda虚拟环境安装
不建议使用root用户安装,因为从安全性、冲突和环境隔离等角度考虑,使用普通用户安装Anaconda更合适,这也是官方推荐的行为。以下为安装命令:
wget https://repo.anaconda.com/archive/Anaconda3-2022.10-Linux-x86_64.sh
sh Anaconda3-2022.10-Linux-x86_64.sh网络问题配置代理
PyTorch安装
建议直接按照PyTorch官网指示的安装命令进行安装。

conda create –n pytorch python=3.9
conda install pytorch torchvision torchaudio pytorch-cuda=11.6 -c pytorch -c nvidia
# 验证安装
python3 -c "import torch; print(torch.cuda.is_available())"TensorFlow安装
conda create -n tf python=3.9
conda activate tf
conda install -c conda-forge cudatoolkit=11.2.2 cudnn=8.1.0
mkdir -p $CONDA_PREFIX/etc/conda/activate.d
echo 'export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$CONDA_PREFIX/lib/' > $CONDA_PREFIX/etc/conda/activate.d/env_vars.sh重新登陆终端
conda activate tf
python3 -m pip install tensorflow==2.10
# 验证安装
python3 -c "import os; os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'; import tensorflow as tf; print('Num GPUs Available: ', len(tf.config.list_physical_devices('GPU')))"Docker容器启用GPU加速支持 (即nvidia-container-toolkit的安装和配置)
介绍。TAO&NGC介绍
安装时需要root权限
sudo curl https://get.docker.com | sh
sudo systemctl --now enable docker将当前用户加入docker用户组(安装Docker后会自动创建docker用户组),以。
# Enable docker to run without root permissions
sudo groupadd docker
sudo usermod -aG docker $USER确定Docker服务是否正常运行
docker run hello-world你
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list你
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker验证安装结果。在Docker容器中运行nvidia-smi命令,以检查GPU在容器中是否可用。
docker run --rm --runtime=nvidia --gpus all nvidia/cuda:11.6.2-base-ubuntu20.04 nvidia-smi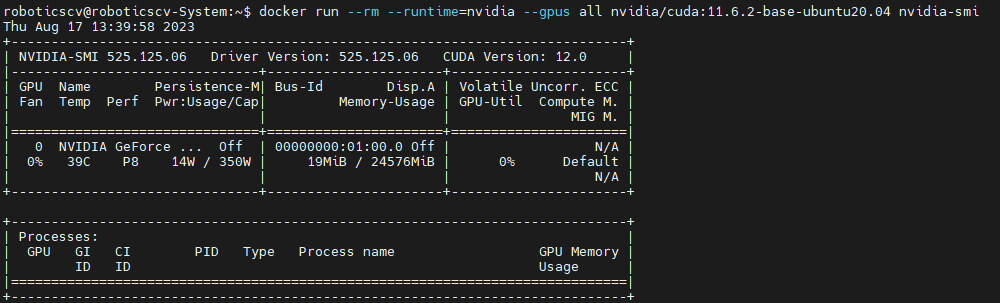
上面这段命令的参数具体如下:
- docker run:运行一个新的Docker容器。
- –rm:在容器退出后自动删除容器。
- –runtime=nvidia:指定使用NVIDIA容器运行时来运行容器,以便在容器中使用GPU。
- –gpus all:指定将所有可用的GPU分配给容器。这样容器就可以访问并利用所有可用的GPU。
- nvidia/cuda:11.6.2-base-ubuntu20.04:指定使用的映像,这里使用的是基于Ubuntu 20.04、安装有11.6.2版本CUDA的映像。
- nvidia-smi:在容器中执行的命令,即运行nvidia-smi以显示GPU的状态信息。
至此,此篇文章的全部配置工作已经完成,接下来就可以快乐地进行模型训练,或者部署PyTorch/TensorFLow模型进行推理啦。小编就迫不及待地部署了ChatGLM2-6B,一个拥有62 亿参数的开源AI大语言模型!如下:
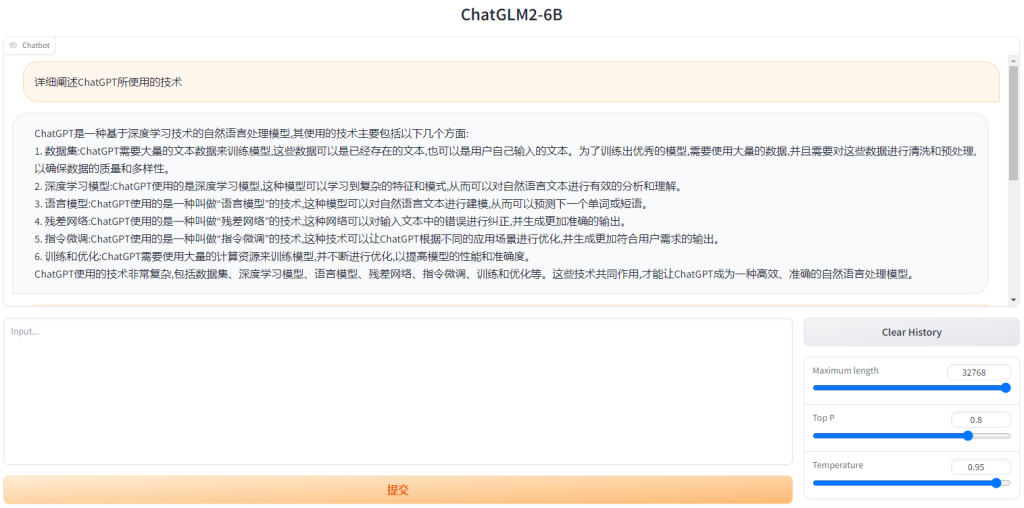
这里有个小建议,若部署新模型时依赖项比较多,建议使用 Virtualenv 在工程目录下创建一个虚拟环境,这个虚拟环境是可以和 Anaconda 虚拟环境共存的。如下图所示,我先进入名称为 “pytorch” 的虚拟环境,随后又进入名称为 “venv” 的虚拟环境(这何尝不是一种套娃!):

当然,退出虚拟环境的时候也旧需要敲两次退出的命令了。先使用deactivate退出 virtualenv 的虚拟环境 “venv”,而后使用conda activate退出 Anaconda 的虚拟环境 “pytorch”。
最近我也准备做一个集成ChatGLM2-6B的ESP32小应用,打算在乐鑫的ESP32Box平台上验证,感兴趣的伙伴可以关注下哦,下一篇文章再见!

参考资源
Install TensorFlow and PyTorch with CUDA, cUDNN, and GPU Support in 3 Easy Steps











请登录后查看评论内容